


- 手机:
- 18888889999
- 电话:
- 0898-66889888
- 邮箱:
- admin@youweb.com
- 地址:
- 海南省海口市玉沙路58号
优化算法的功能,是通过改善训练方式,来最小化(或最大化)损失函数。
1 梯度下降法
缺点:
(1)传统的批量梯度下降将计算整个数据集梯度,但只会进行一次更新,因此在处理大型数据集时速度很慢且难以控制,甚至导致内存溢出。
(2)权重更新的快慢是由学习率η决定的,并且可以在凸面误差曲面中收敛到全局最优值,在非凸曲面中可能趋于局部最优值。
(3)使用标准形式的批量梯度下降还有一个问题,就是在训练大型数据集时存在冗余的权重更新。
2 随机梯度下降法
优点:
随机梯度下降对每个训练样本进行参数更新,每次执行都进行一次更新,且执行速度更快。频繁的更新使得参数间具有高方差,损失函数会以不同的强度波动。这实际上是一件好事,因为它有助于我们发现新的和可能更优的局部最小值,而标准梯度下降将只会收敛到某个局部最优值。
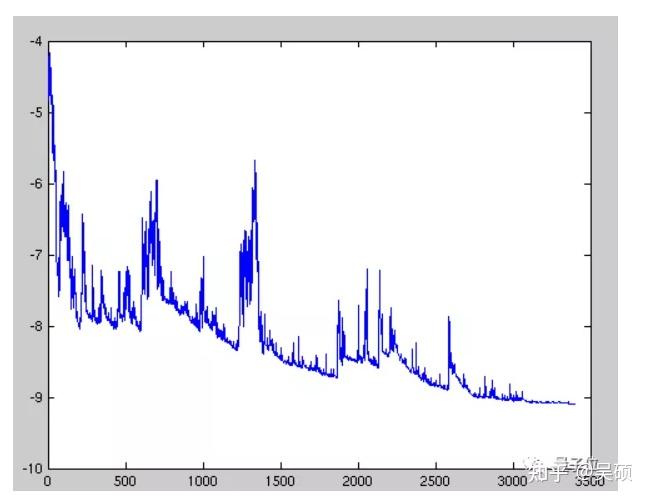
缺点:
如图所示,每个训练样本中高方差的参数更新会导致损失函数大幅波动,因此我们可能无法获得给出损失函数的最小值。只能获得在一定区间波动的损失值。
3 批量梯度下降
为了避免方法12下降中存在的问题,一个改进方法为小批量梯度下降(Mini Batch Gradient Descent),对每个批次中的n个训练样本执行一次更新。
优点:
(1)可以减少参数更新的波动,最终得到效果更好和更稳定的收敛。
(2)可以使用最新的深层学习库中通用的矩阵优化方法,使计算小批量数据的梯度更加高效。在训练神经网络时,通常都会选择小批量梯度下降算法。
使用梯度下降及其变体时面临的挑战
(1)很难选择出合适的学习率。太小的学习率会导致网络收敛过于缓慢,而学习率太大可能会影响收敛,并导致损失函数在最小值上波动,甚至出现梯度发散。
(2)相同的学习率并不适用于所有的参数更新。如果训练集数据很稀疏,且特征频率非常不同,则不应该将其全部更新到相同的程度,但是对于很少出现的特征,应使用更大的更新率。
(3)在神经网络中,最小化非凸误差函数的另一个关键挑战是避免陷于多个其他局部最小值中。实际上,问题并非源于局部极小值,而是来自鞍点,即一个维度向上倾斜且另一维度向下倾斜的点。这些鞍点通常被相同误差值的平面所包围,这使得SGD算法很难脱离出来,因为梯度在所有维度上接近于零。
4 动量梯度下降法
动量梯度下降法运行速度几乎总是快于标准的梯度下降算法。例如,如果你要优化成本函数,函数形状如下图,红点代表最小值的位置,假设你从这里(蓝色点)开始梯度下降法,如果进行梯度下降法的一次迭代,无论是batch或mini-batch下降法,最后会指向这里红色点,但你会发现梯度下降法要走很多步骤?
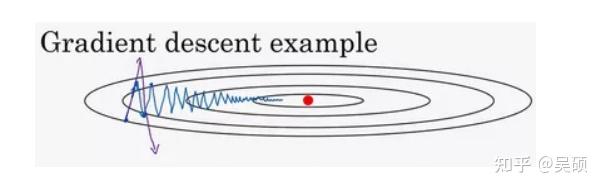
如果你要用较大的学习率(紫色箭头),结果可能会偏离函数的范围,为了避免摆动过大,你要用一个较小的学习率。另一个看待问题的角度是,在纵轴上,你希望学习慢一点,因为你不想要这些摆动,但是在横轴上,你希望加快学习,你希望快速从左向右移,移向最小值,移向红点。
SGD方法中的高方差振荡使得网络很难稳定收敛,所以有研究者提出了一种称为动量(Momentum)的技术,通过优化相关方向的训练和弱化无关方向的振荡(上图中就是强化横轴方向训练),来加速SGD训练。动量算法引入了变量 v 充当速度角色——它代表参数在参数空间移动的方向和速率。速度被设为负梯度的指数衰减平均。名称动量(momentum)。

参考自百面机器学习
5 Nesterov梯度加速法
在该方法中,与方法4的区别是他提出先根据之前的动量进行大步跳跃,然后计算梯度进行校正,从而实现参数更新。这种预更新方法能防止大幅振荡,不会错过最小值,并对参数更新更加敏感。
方法4

方法5
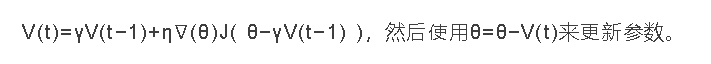
6 Adagrad
Adagrad方法是通过历史梯度平方和来调整合适的学习率η,对稀疏参数进行大幅更新和对频繁参数进行小幅更新。因此,Adagrad方法非常适合处理稀疏数据。

7 Adam


个人认为是使用一阶矩增加了动量法的优化方向,使用二阶矩增加了Adagrad的自适应学习率,Adam为两种方法的 结合。
每个优化方法的具体步骤可以去参考:
百面机器学习
花书




