


- 手机:
- 18888889999
- 电话:
- 0898-66889888
- 邮箱:
- admin@youweb.com
- 地址:
- 海南省海口市玉沙路58号
LRU算法全称是最近最少使用算法(Least Recently Use),广泛的应用于缓存机制中。当缓存使用的空间达到上限后,就需要从已有的数据中淘汰一部分以维持缓存的可用性,而淘汰数据的选择就是通过LRU算法完成的。
LRU算法的基本思想是基于局部性原理的时间局部性:
如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
所以顾名思义,LRU算法会选出最近最少使用的数据进行淘汰。
一般来讲,LRU将访问数据的顺序或时间和数据本身维护在一个容器当中。当访问一个数据时:
- 该数据不在容器当中,则设置该数据的优先级为最高并放入容器中。
- 该数据在容器当中,则更新该数据的优先级至最高。
当数据的总量达到上限后,则移除容器中优先级最低的数据。下图是一个简单的LRU原理示意图:
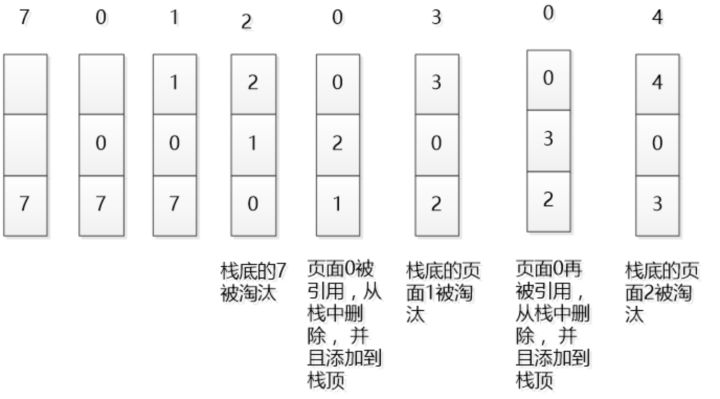
如果我们按照的顺序来访问数据,且数据的总量上限为3,则如上图所示,LRU算法会依次淘汰这三个数据。
那么我们现在就按照上面的原理,实现一个朴素的LRU算法。下面有三种方案:
-
基于数组
方案:为每一个数据附加一个额外的属性——时间戳,当每一次访问数据时,更新该数据的时间戳至当前时间。当数据空间已满后,则扫描整个数组,淘汰时间戳最小的数据。
不足:维护时间戳需要耗费额外的空间,淘汰数据时需要扫描整个数组。
-
基于长度有限的双向链表
方案:访问一个数据时,当数据不在链表中,则将数据插入至链表头部,如果在链表中,则将该数据移至链表头部。当数据空间已满后,则淘汰链表最末尾的数据。
不足:插入数据或取数据时,需要扫描整个链表。
-
基于双向链表和哈希表
方案:为了改进上面需要扫描链表的缺陷,配合哈希表,将数据和链表中的节点形成映射,将插入操作和读取操作的时间复杂度从O(N)降至O(1)
下面我们就基于双向链表和哈希表实现一个LRU算法
基本上就是把上述LRU算法思路用代码实现了一遍,比较简单,只需要注意一下pre和next两个指针的指向和同步更新哈希表,put()和get()操作的时间复杂度都是O(1),空间复杂度为O(N)。
其实我们可以直接根据JDK给我们提供的LinkedHashMap直接实现LRU。因为LinkedHashMap的底层即为双向链表和哈希表的组合,所以可以直接拿来使用。
默认LinkedHashMap并不会淘汰数据,所以我们重写了它的removeEldestEntry()方法,当数据数量达到预设上限后,淘汰数据,accessOrder设为true意为按照访问的顺序排序。整个实现的代码量并不大,主要都是应用LinkedHashMap的特性。
正因为LinkedHashMap这么好用,所以我们可以看到Dubbo的LRU缓存LRUCache也是基于它实现的。
朴素的LRU算法已经能够满足缓存的要求了,但是还是有一些不足。当热点数据较多时,有较高的命中率,但是如果有偶发性的批量操作,会使得热点数据被非热点数据挤出容器,使得缓存受到了“污染”。所以为了消除这种影响,又衍生出了下面这些优化方法。
LRU-K算法是对LRU算法的改进,将原先进入缓存队列的评判标准从访问一次改为访问K次,可以说朴素的LRU算法为LRU-1。
LRU-K算法有两个队列,一个是缓存队列,一个是数据访问历史队列。当访问一个数据时,首先先在访问历史队列中累加访问次数,当历史访问记录超过K次后,才将数据缓存至缓存队列,从而避免缓存队列被污染。同时访问历史队列中的数据可以按照LRU的规则进行淘汰。具体如下图所示:
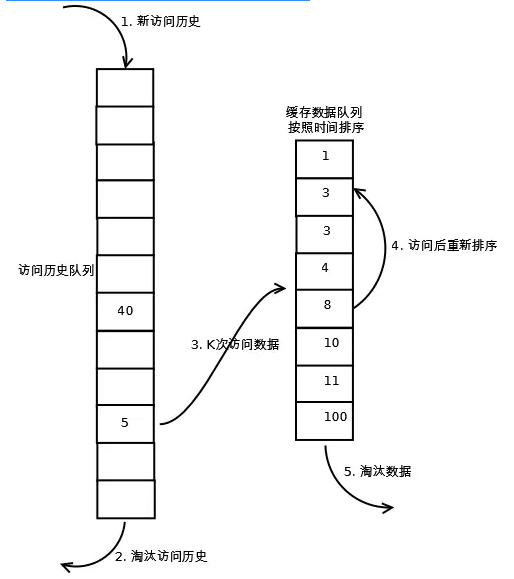
下面我们来实现一个LRU-K缓存:
上面只是个简单的模型,并没有加上必要的并发控制。
一般来讲,当K的值越大,则缓存的命中率越高,但是也会使得缓存难以被淘汰。综合来说,使用LRU-2的性能最优。
Two Queue可以说是LRU-2的一种变种,将数据访问历史改为FIFO队列。好处的明显的,FIFO更简易,耗用资源更少,但是相比LRU-2会降低缓存命中率。
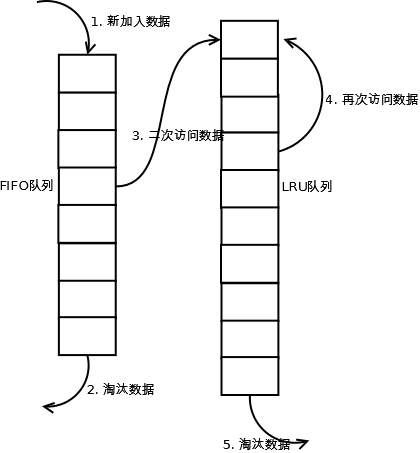
这里直接继承LinkedHashMap,并且accessOrder默认为false,意为按照插入顺序进行排序,二者结合即为一个FIFO的队列。通过重写removeEldestEntry()方法来自动淘汰最早插入的数据。
相比于上面两种优化,Multi Queue的实现则复杂的多,顾名思义,Multi Queue是由多个LRU队列组成的。每一个LRU队列都有一个相应的优先级,数据会根据访问次数计算出相应的优先级,并放在该队列中。
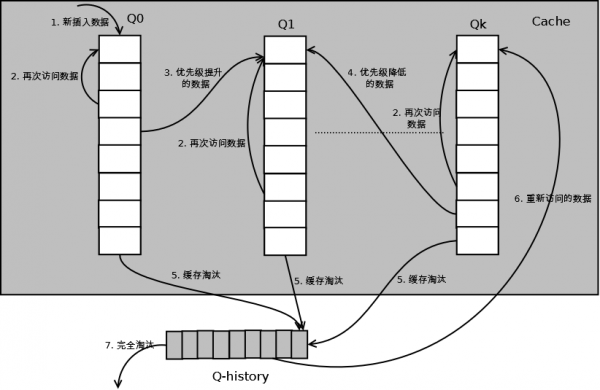
-
数据插入和访问:当数据首次插入时,会放入到优先级最低的Q0队列。当再次访问时,根据LRU的规则,会移至队列头部。当根据访问次数计算的优先级提升后,会将该数据移至更高优先级的队列的头部,并删除原队列的该数据。同样的,当该数据的优先级降低时,会移至低优先级的队列中。
-
数据淘汰:数据淘汰总是从最低优先级的队列的末尾数据进行,并将它加入到Q-history队列的头部。如果数据在Q-history数据中被访问,则重新计算该数据的优先级,并将它加入到相应优先级的队列中。否则就是按照LRU算法完全淘汰。
Multi Queue也可以看做是LRU-K的变种,将原来两个队列扩展为多个队列,好处就是无论是加入缓存还是淘汰缓存数据都变得更加细腻,但是会带来额外开销。
本文讲解了基本的LRU算法及它的几种优化策略,并比较了他们之间的异同和优劣。以前没有想到LRU还有这么些门道,后续还会有Redis、Mysql对于LRU算法应用的文章。




