


- 手机:
- 18888889999
- 电话:
- 0898-66889888
- 邮箱:
- admin@youweb.com
- 地址:
- 海南省海口市玉沙路58号
的优化器:管理并更新模型中可学习参数的值,使得模型输出更接近真实标签
导数:函数在指定坐标轴上的变化率
方向导数:指定方向上的变化率(二元及以上函数,偏导数)
梯度:一个向量,方向是使得方向导数取得最大值的方向

参数
- defaults:优化器超参数
- state:参数的缓存,如momentum的缓存
- :管理的参数组
- _step_count:记录更新次数,学习率调整中使用
基本方法:
- zero_grad():清空所管理参数的梯度

特性:张量梯度不会自动清零
step():执行一步更新
:添加参数组

:获取优化器当前状态信息字典

:加载状态信息字典
使用代码帮助理解和学习
1 | import os |
上面学习率是1,把学习率改为0.1试一下
1 | optimizer=optim.SGD([weight], lr=0.1) |
接着上面的代码,我们再看一下方法
1 | # add_param_group方法 |
关于、、、这几个方法比较简单就不再赘述。
learning_rate学习率
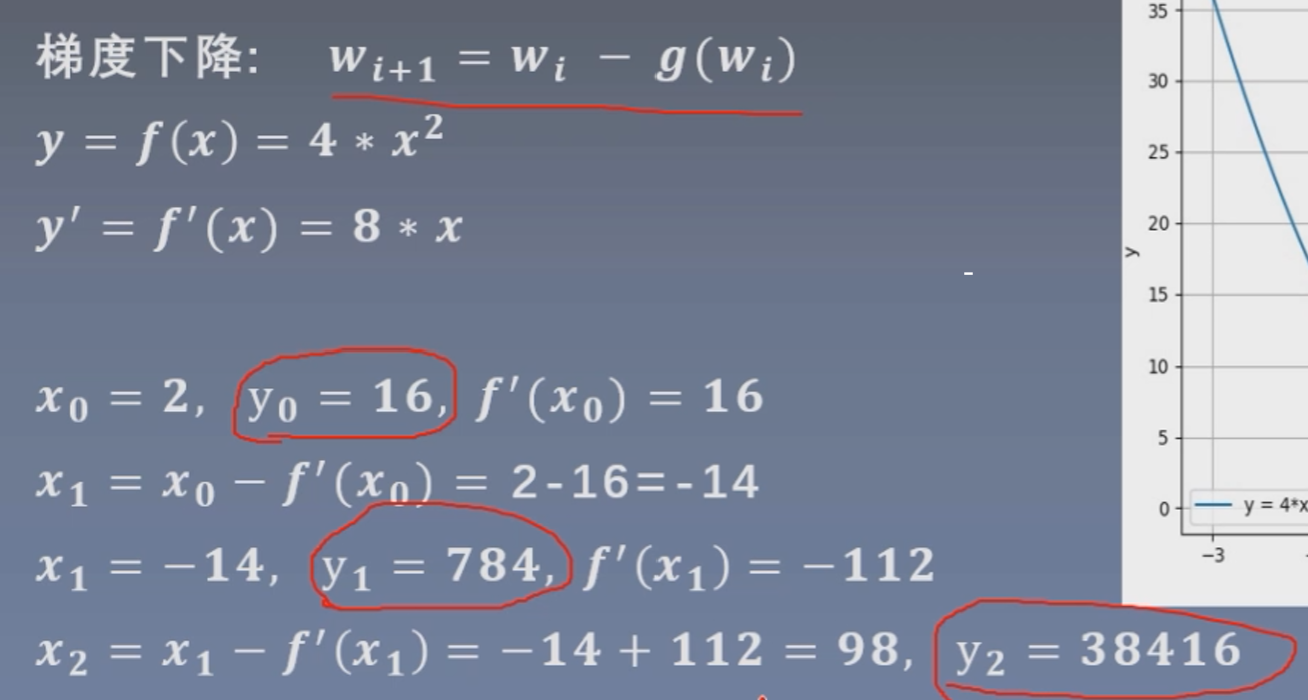
这里学习率为1,可以看到并没有达到梯度下降的效果,反而y值越来越大,这是因为更新的步伐太大。

我们以这个函数举例,将y值作为要优化的损失值,那么梯度下降的过程就是为了找到y的最小值(即此函数曲线的最小值);如果我们把学习率设置为0.2,就可以得到这样一个梯度下降的图
1 | def func(x): |
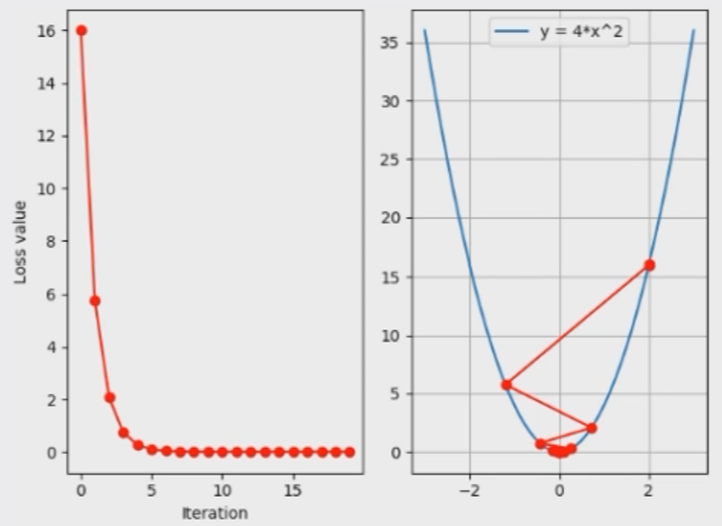
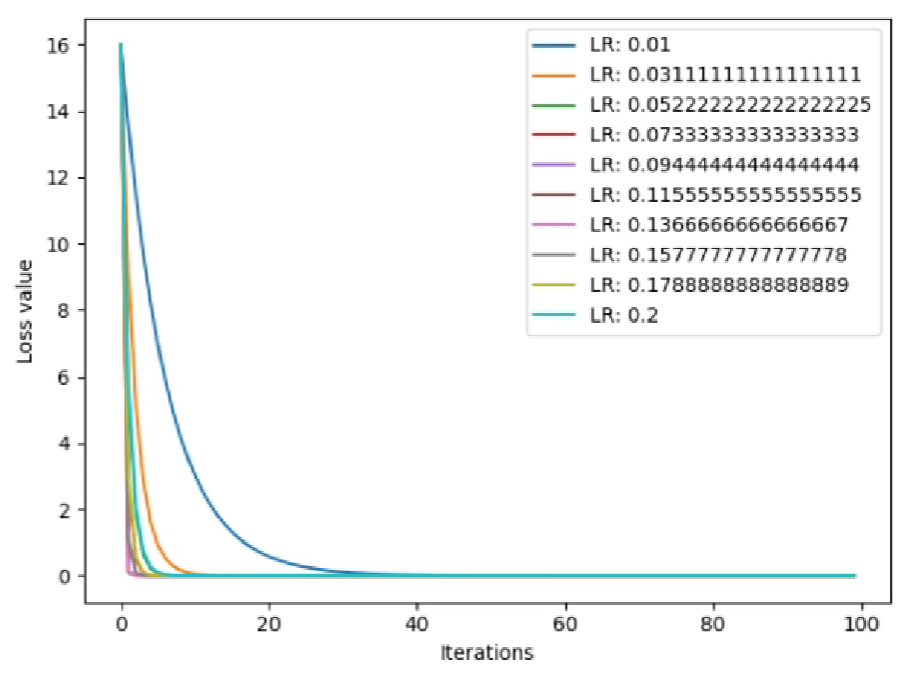
这里其实存在一个下降速度更快的学习率,那就是0.125,一步就可以将loss更新为0,这是因为我们已经了这个函数表达式,而在实际神经网络模型训练的过程中,是不知道所谓的函数表达式的,所以只能选取一个相对较小的学习率,然后以训练更多的迭代次数来达到最优的loss。
动量(Momentum,又叫冲量)
结合当前梯度与上一次更新信息,用于当前更新
为什么会出现动量这个概念?
当学习率比较小时,往往更新比较慢,通过引入动量,使得后续的更新受到前面更新的影响,可以更快的进行梯度下降。
指数加权平均:当前时刻的平均值(Vt)与当前参数值(θ)和前一时刻的平均值(Vt-1)的关系。
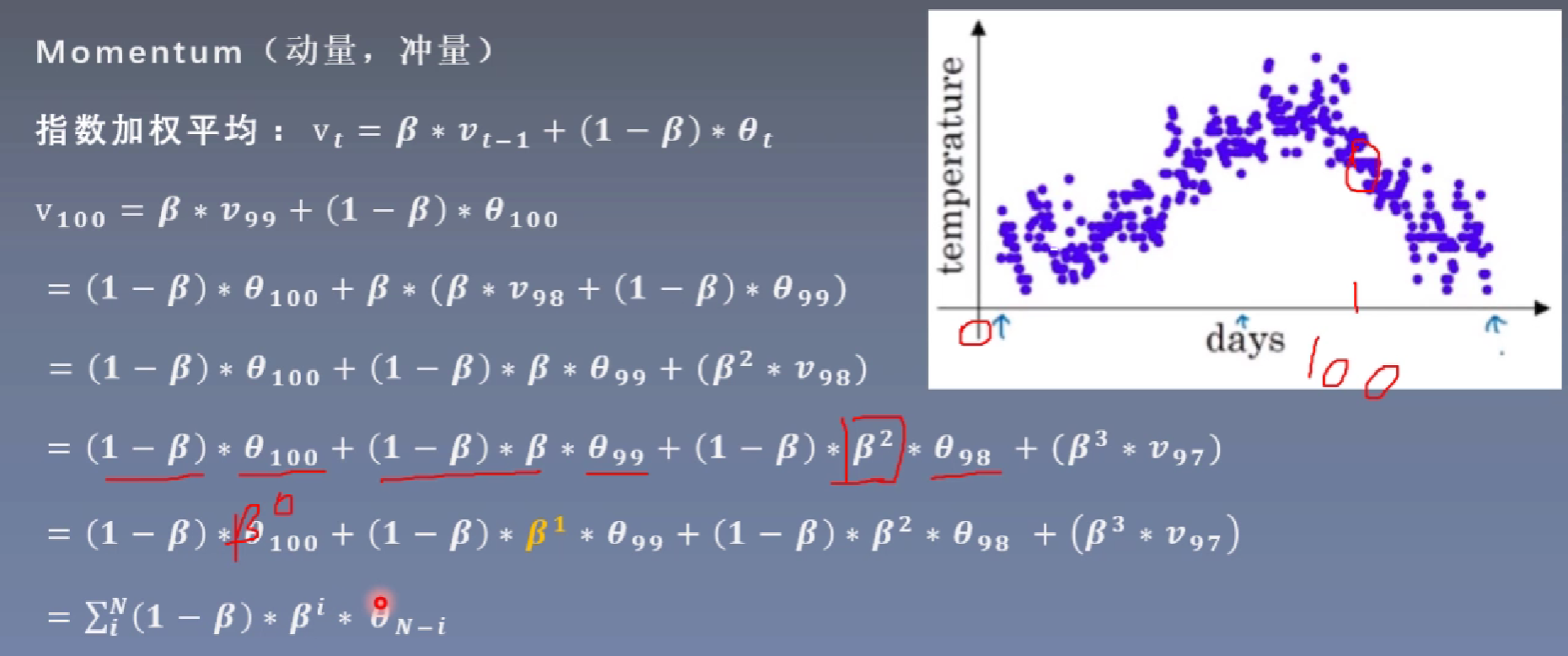
根据上述公式进行迭代展开,因为0<β<1,当前时刻的平均值受越近时刻的影响越大(更近的时刻其所占的权重更高),越远时刻的影响越小,我们可以通过下面作图来看到这一变化。
1 | import numpy as np |
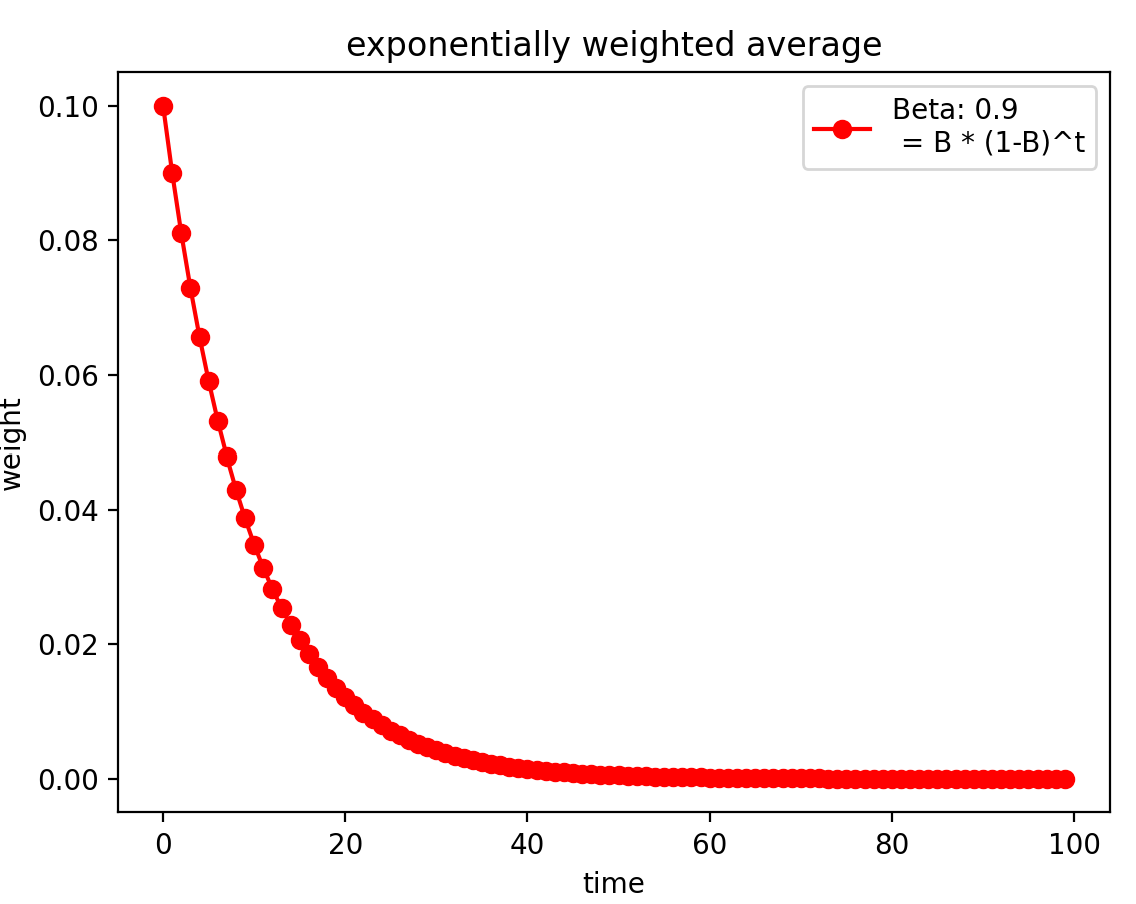
这里β是一个超参数,设置不同的值,其对于过去时刻的权重计算如下图
1 | beta_list=[0.98, 0.95, 0.9, 0.8] |
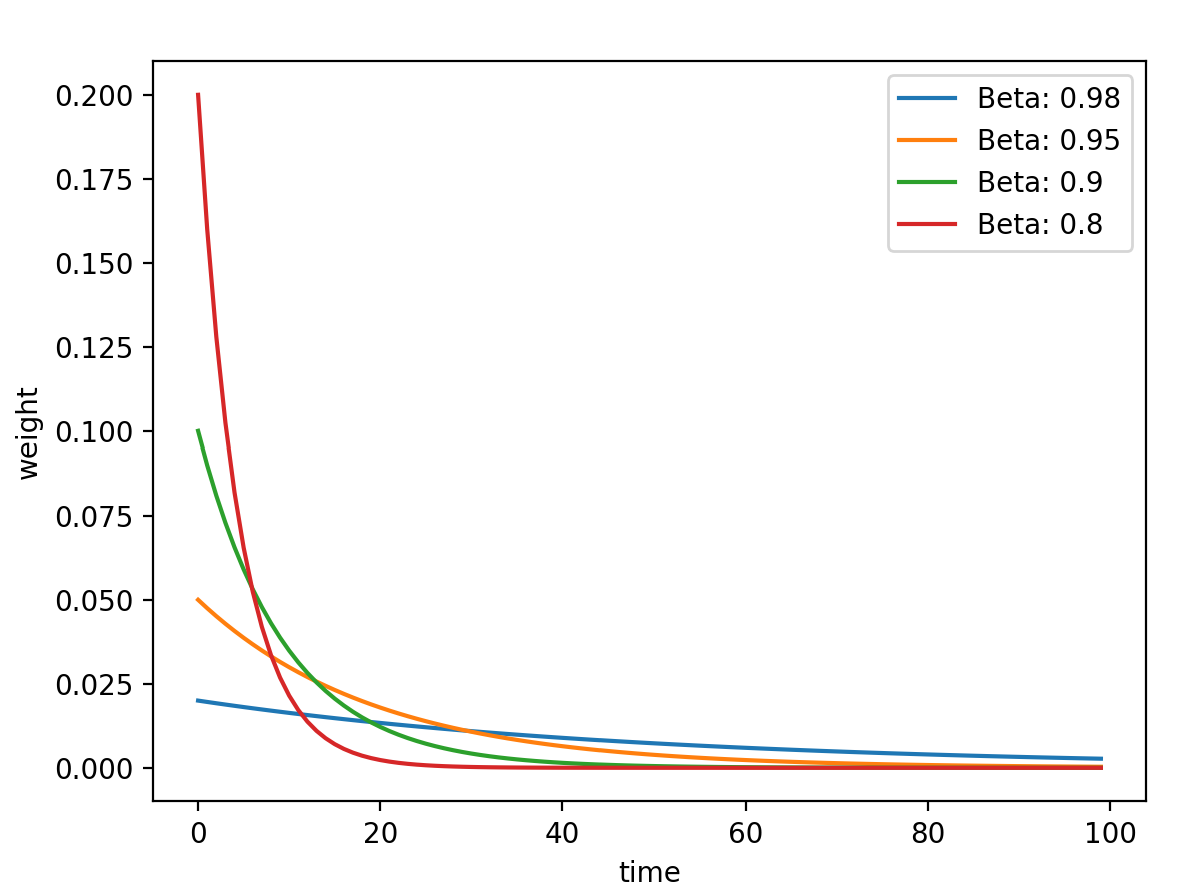
从图中可以得到这一结论:β值越小,记忆周期越短,β值越大,记忆周期越长。
中带有momentum参数的更新公式
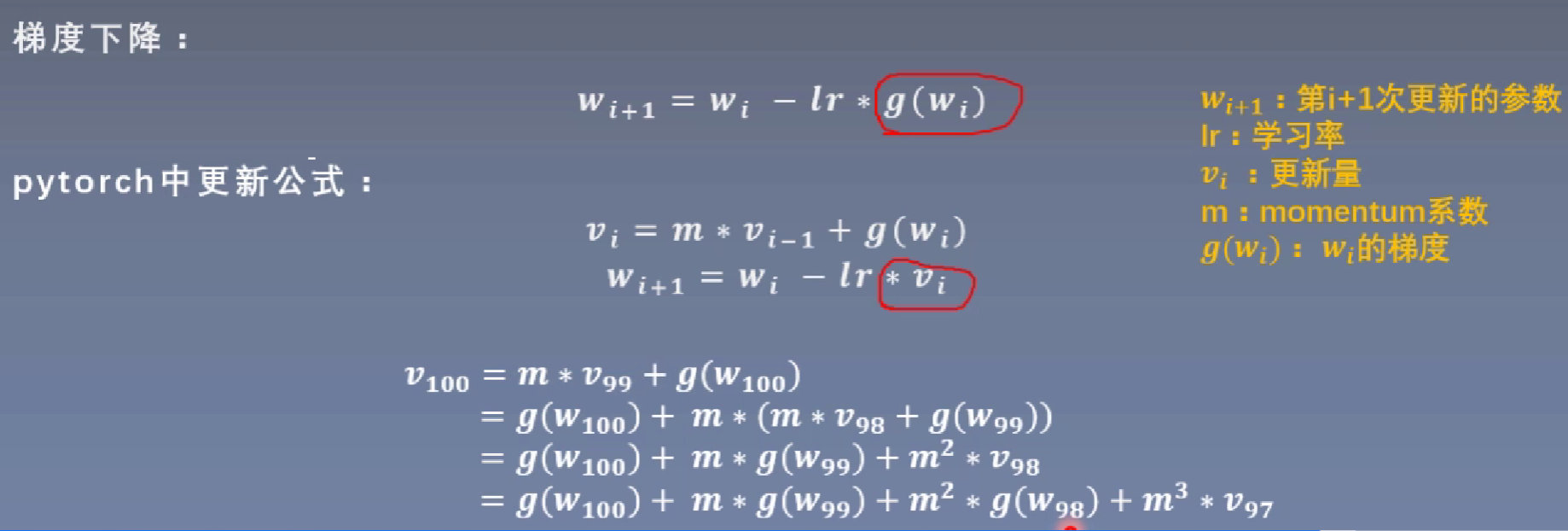
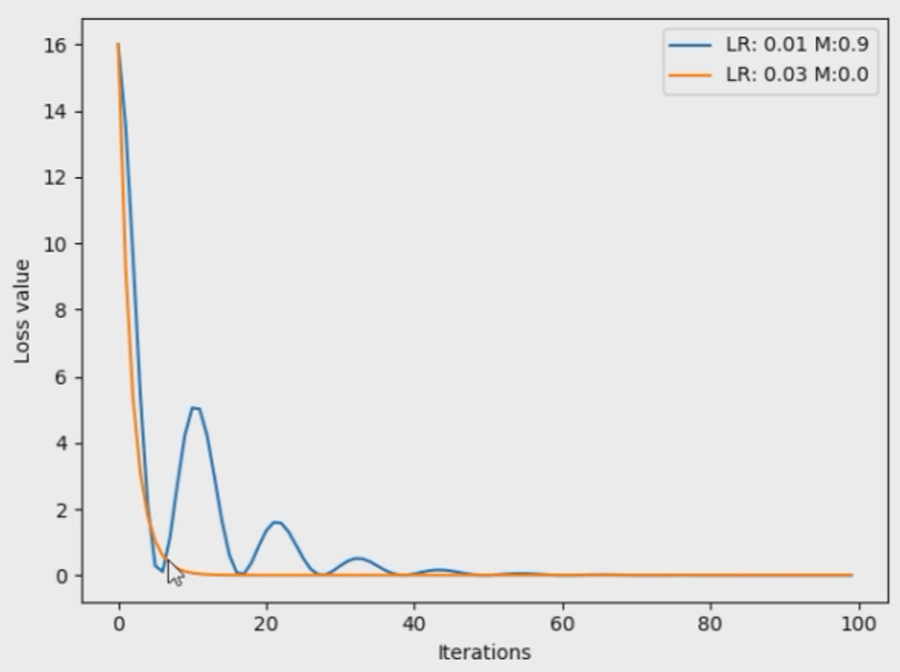
对于这个例子,在没有momentum时,我们对比学习率分别为0.01和0.03会发现,0.03收敛的更快。
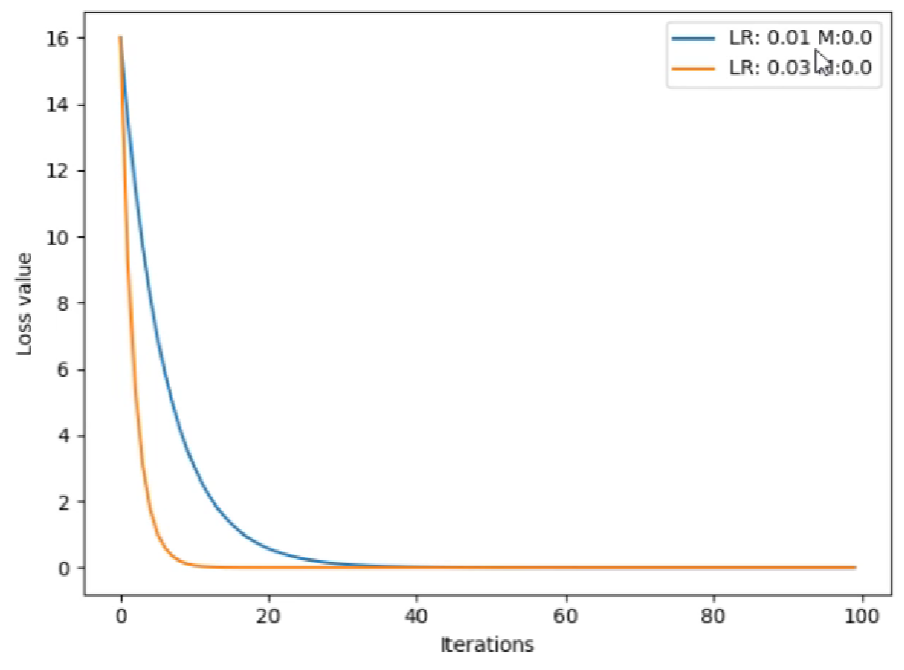
如果我们给learning_rate=0.01增加momentum参数,会发现其可以先一步0.03的学习率到达loss的较小值,但是因为动量较大的因素,在达到了最小值后还会反弹到一个大的值。
中的优化器
主要参数:
- :管理的参数组
- :学习率
- momentum:动量系数,贝塔
- :正则化系数
- :是否采用NAG,默认False
:自适应学习率梯度下降法
:Adagrad的改进
:Adagrad的改进
:RMSprop结合Momentum
:Adam增加学习率上限
:稀疏版的Adam
:随机平均梯度下降
:弹性反向传播
:BFGS的改进
前期学习率大,后期学习率小
中调整学习率的基类
主要属性:
- optimizer:关联的优化器
- last_epoch:记录epoch数
- :记录初始学习率
主要方法:
- step():更新下一个epoch的学习率
- :虚函数,计算下一个epoch的学习率
等间隔调整学习率
主要参数:
- step_size:调整间隔数
- gamma:调整系数
调整方式:
1 | import torch |
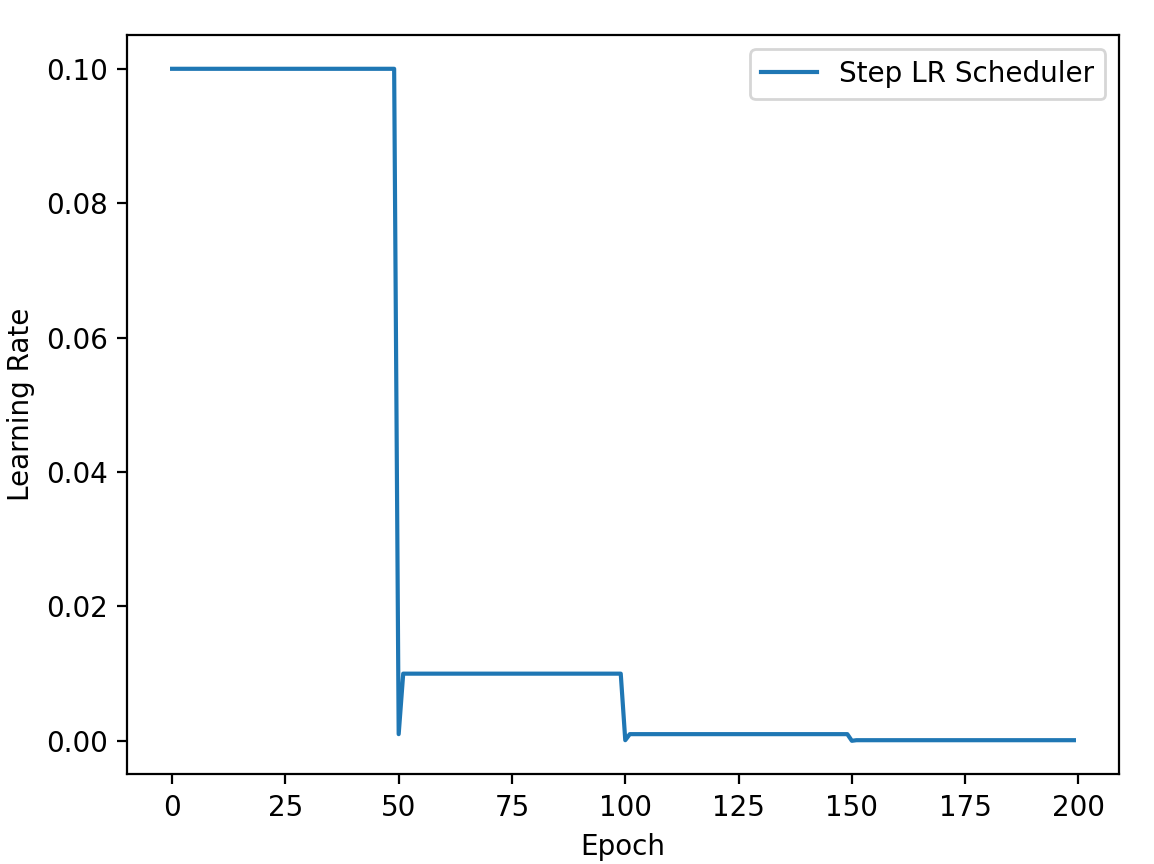
功能:按给定间隔调整学习率
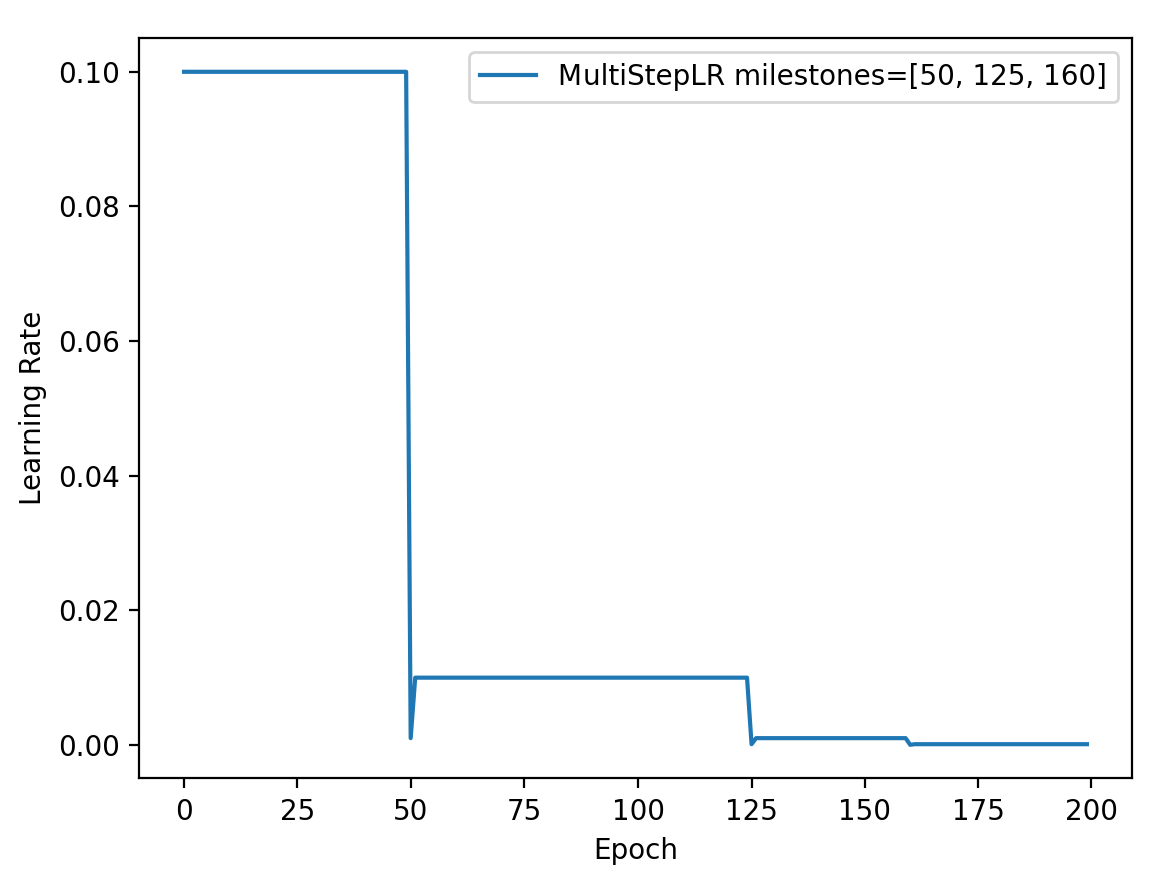
主要参数:
- milestones:设定调整时刻数
- gamma:调整系数
调整方式:
1 | # MultiStepLR |
只需要改变这里代码,其他部分与中基本一致
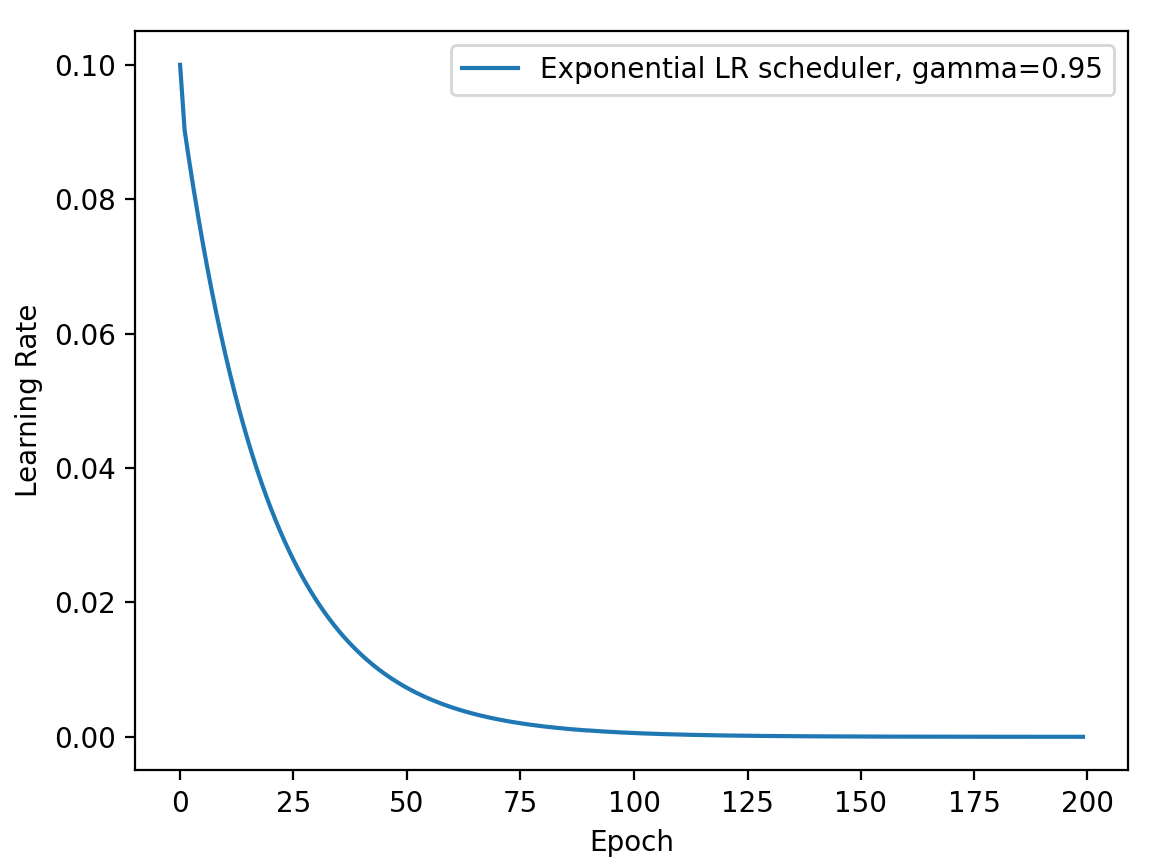
功能:按指数衰减调整学习率
主要参数:
- gamma:指数的底
调整方式:
1 | # Exponential LR |
功能:余弦周期调整学习率
主要参数:
- T_max:下降周期
- eta_min:学习率下限
调整方式:
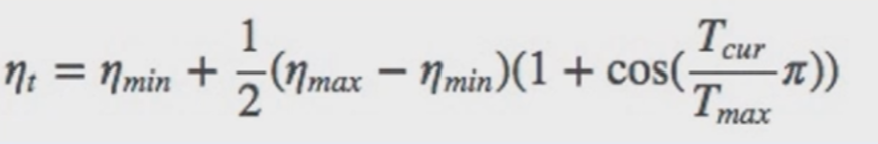
1 | # CosineAnnealingLR |
功能:监控指标,当指标不再变化则调整学习率
主要参数:
- :min/max,两种模式,min观察下降,max观察上升
- factor:调整系数
- patience:“耐心”,接受几次不变化
- :“冷却时间”,停止监控一段时间
- verbose:是否打印日志
- :学习率下限
- :学习率衰减最小值
1 | # Reduce LR on Plateau |
功能:自定义调整策略
主要参数:
- :function or list
1 | # lambda LR |
transformer包中的
我们都知道模型在开始时可以采用较大的学习率,然后快速的收敛,随着模型训练到后期需要减少学习率才能使得模型进一步学习,如果持续使用较大的学习率会使得模型最后无法走到一个局部的最优点,所以有一种叫做的学习率调整策略,偏向于前期采用较大的学习率,后期逐渐减小学习率。
在transformer包中就已经封装了类似的方法:
1 | import transformers |
这里我们详细看一下来进一步理解该方法是如何调整学习率的。
1 | from transformers import AdamW, get_linear_schedule_with_warmup |
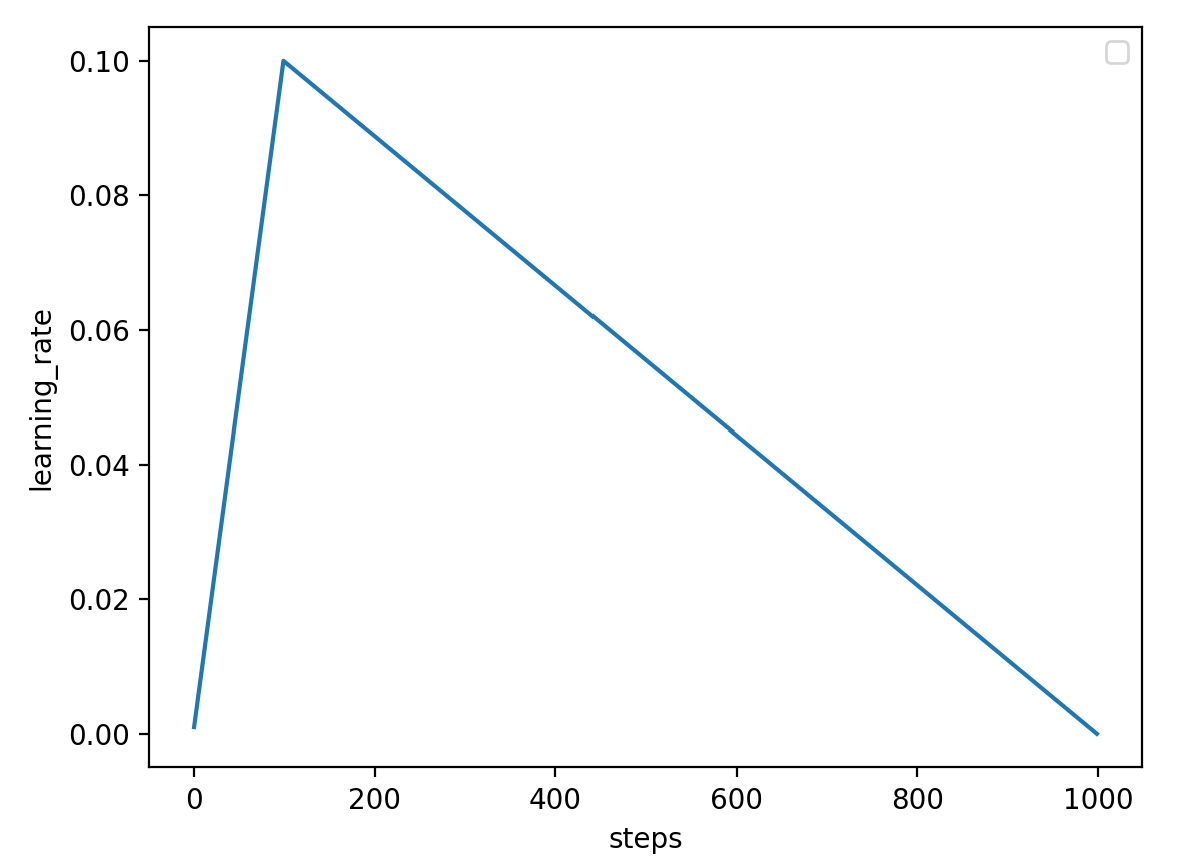
可以看到,根据我们预先设置在总的训练步数的一个比例上,这里是1000的10%,那就是前100步,学习率是从0线性的增长到我们预先设定的学习率,之后线性的减小到0。
当参数设置为0时,learning rate没有预热的上升过程,只有从初始设定的learning rate 逐渐衰减到0的过程,也就是get_constant_schedule方法。
那其实还有一个问题,类似Adam之类的优化器,本身不是自适应学习率的吗?为什么还需要再引入相关方法来调整学习率呢?
因为常用的神经网络优化器Adam的自适应学习率并不是真正意义上的自适应。
从统计的角度看,Adam的自适应原理也是根据统计对梯度进行修正,但依然离不开前面设置的学习率。如果学习率设置的过大,则会导致模型发散,造成收敛较慢或陷入局部最小值点,因为过大的学习率会在优化过程中跳过最优解或次优解。
所以Adam在调整学习率时也是根据预先设置的学习率来调整的,如果我们本身可以控制学习率的变化,再通过Adam来微调可以得到更好的效果。




